.webp)
.svg)
.svg)

Previous Post

When does owning compute beat AI LLM subscriptions?
AI coding subscriptions run roughly $100-200 per developer per month, and the metered token usage on top tends to climb as agentic workflows consume more per task. For a 10-engineer team, running an open-source coding model on owned or cheaper compute can come in 30-60% lower, so the question is when that tradeoff is worth it.
Anthony C.
June 4, 2026
What's happened on the open-source side
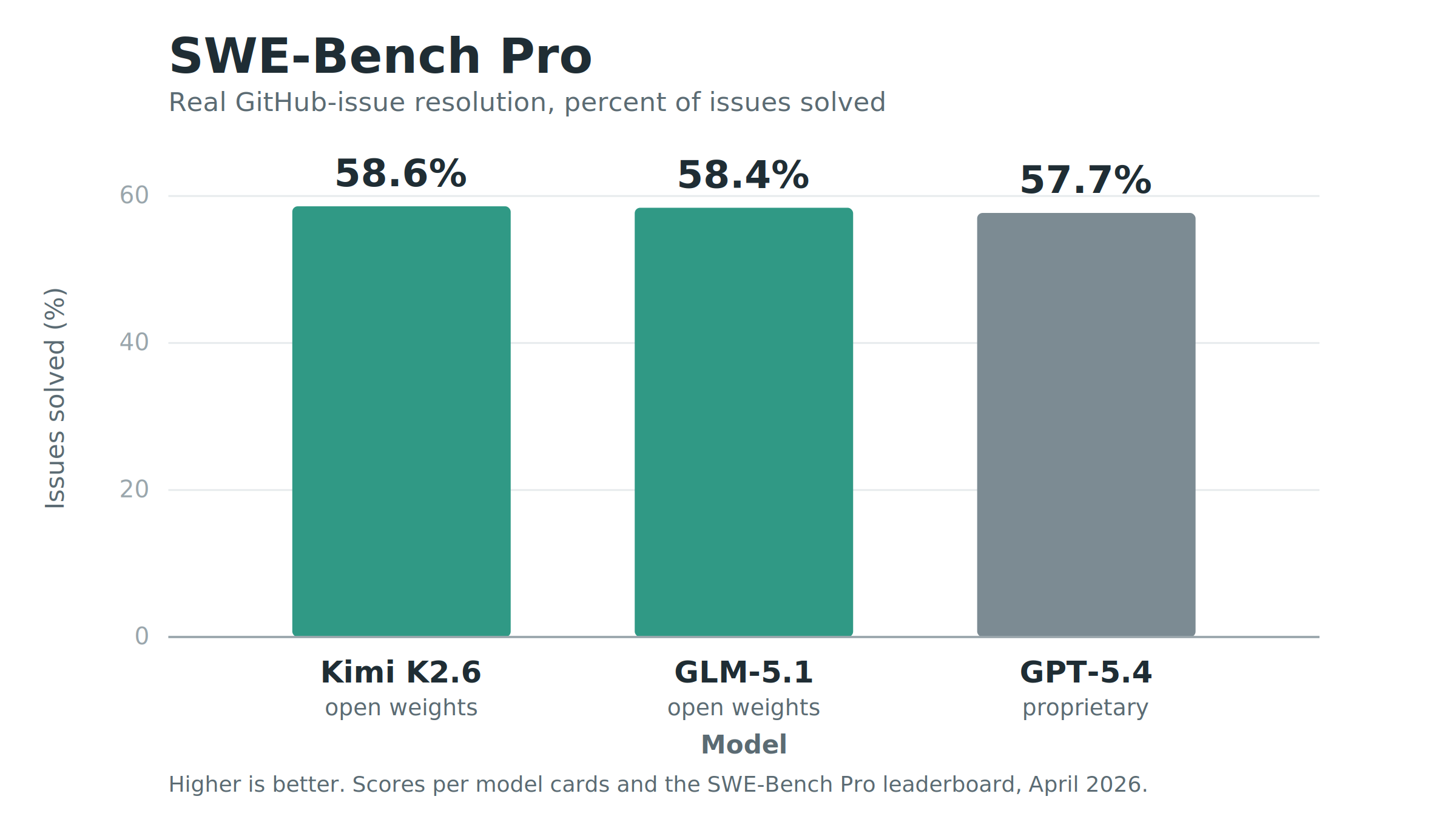
The open models with the attention right now are GLM-5.1 from Z.ai and Kimi K2.6 from Moonshot, both released in April 2026. On SWE-Bench Pro, the benchmark the field moved to after OpenAI stopped reporting Verified scores, Kimi K2.6 scores 58.6% and GLM-5.1 scores 58.4%, with both edging out GPT-5.4 (57.7%) and leading Claude Opus 4.6 on real GitHub-issue resolution. Both are large Mixture-of-Experts models (GLM-5.1 at roughly 750B parameters with 40B active, Kimi K2.6 at 1T with 32B active), so they run on a cluster rather than a single card, but the weights are open and API access runs around $4 per million tokens, roughly 70-80% below comparable proprietary pricing.
That changes the cost question more than the benchmark does. The gap to the proprietary frontier on routine coding has narrowed to where the deciding factor for most teams is token economics rather than capability.
For teams that want to self-host on modest hardware instead of calling an API, the smaller open models are the relevant ones. Devstral Small 2 (24B) from Mistral runs on a single RTX 4090 or a 32GB Mac and scores in the high-60s on SWE-bench Verified, and Qwen 3.6 coding variants are competitive on LiveBench Coding. They don't match the frontier on hard reasoning, but for refactoring, test generation, boilerplate, and code-review pre-passes they tend to be a reasonable fit.
None of the open models close the gap with Opus 4.7 on the hardest reasoning. SWE-bench itself has known limitations (one analysis found 59.4% of the hardest unsolved Verified problems had flawed test cases, part of why the field shifted to Pro), so treat the numbers as directional rather than precise.
The cost back-of-envelope
For a 10-engineer team managing AI coding subscriptions, real spend lands at $25-50K/year depending on usage and overages. The seat floor alone is around $24-30K/year once heavier users move to higher tiers, and metered token usage makes the all-in number both bigger and more variable.
A self-hosted alternative running a self-hostable open model like Devstral Small 2 or a Qwen coding variant on a single H100 needs roughly one GPU-hour per developer per day on bursty workloads. With H100 on-demand pricing at neoclouds running around $1.60-1.95/GPU-hour in Q2 2026, and lower rates available on reserved capacity or owned hardware, that comes to about $40-60/developer/month on the high end, or $4.8-7.2K/year for the team. Two H100s for redundancy and headroom roughly doubles that to $10-14K. Add a platform engineer's time to maintain the deployment (5-10% of one engineer's salary, call it $10-15K/year fully loaded), and the all-in cost lands in the $20-30K/year range.
That works out to roughly a 30-60% reduction against the subscription path at on-demand neocloud pricing, and meaningfully more for teams with access to reserved capacity, owned hardware, or sovereign infrastructure. The high end of that range, around 50-70%, shows up when teams run on owned compute rather than rented capacity. The exact number for a given team depends on usage intensity, team size, and whether token overages were already pushing subscription costs toward the high end.
What changes the answer for different teams
Workload shape. Bursty coding sessions, which describes most engineering teams, share GPU capacity well across developers. Sustained heavy multi-agent workflows like autonomous coding pipelines or large refactoring runs consume GPU time closer to one-to-one, which moves the breakeven point back toward subscriptions.
Frontier reasoning frequency. Tasks that need Opus 4.7-tier reasoning don't have a clean open-source substitute yet. If 20%+ of a team's work falls in that category, the subscription path still wins for the high-end work, and the question becomes hybrid routing rather than full migration.
Data sensitivity. Teams handling proprietary code or regulated data often want it not to leave their environment. The cost calculation matters less here; the deployment is happening regardless.
Platform engineering capacity. Running an inference deployment is engineering work. Teams without anyone who can maintain a model-serving stack will burn the cost savings on outages or consultant fees. The OpenClaw analysis put a typical setup at 20 hours of engineering time before ongoing maintenance kicks in.
Team size. Below 5 engineers, the subscription path almost always wins on total cost of ownership. The crossover point depends on usage, but most teams hit it somewhere in the 10-20 engineer range.
Hybrid is the realistic answer for most teams
Few teams should be all-in on either path.
Self-hosted open-source models handle the bulk of routine work like code completion, test generation, refactoring, documentation, and code review pre-passes. This is where the cost reduction lands and where open-source quality is close enough to frontier that the gap doesn't matter day to day.
Subscription access to frontier APIs stays reserved for the work that benefits from frontier reasoning, including architecture decisions, complex multi-file debugging, and agentic workflows that need Opus-tier planning.
The 50-70% reduction assumes the team can route the right work to the right model. Teams that don't build that routing discipline end up paying for the subscription anyway because engineers default to it.
What the numbers don't capture
Latency and ergonomics. Managed AI coding tools have lower setup friction and tighter tooling integration than anything self-hosted out of the box. Self-hosted means a slower path to "engineer opens terminal, agent works." Good platform engineering closes some of that gap, but not for free.
Model improvement cadence. Frontier labs ship better models on their own schedule. Self-hosted teams pin to a specific open-source release until they decide to upgrade. The pin can be a feature (predictable behavior, no surprise regressions) or a problem (missing out on capability jumps), depending on how the team handles change.
Zettabyte helps engineering teams scope and deploy self-hosted coding-model setups on their own compute. Reach out if that's a question your team is working through.
Sources
- Anthropic. Manage costs effectively, Claude Code documentation.
- CloudZero. Claude Pricing in 2026.
- mem0. Claude Pricing: Every Plan and API Cost (May 2026).
- GoSearch. What is Claude Enterprise Pricing in 2026?
- Moonshot AI. Kimi K2.6 release and model card, April 2026 (SWE-Bench Pro 58.6%).
- Z.ai. GLM-5.1 release, April 2026 (SWE-Bench Pro 58.4%); per-token pricing via provider gateways (llm-stats aggregated, May 2026).
- Pinggy. Best Open Source Self-Hosted LLMs for Coding in 2026.
- codeant.ai. SWE-bench Leaderboard 2026. April 2026.
- Public H100 on-demand pricing across neocloud providers, May 2026 (CoreWeave, Lambda, RunPod, Together AI).
- Cognio. OpenClaw vs Claude Code (2026): When Self-Hosted Wins. April 2026.
Tell Us What You’re Building. We’ll Show You How It Runs.

